When designing REST APIs, this has been observed that many people struggle to choose between HTTP PUT or POST methods due to their seemingly similar objectives – both involve sending data to a server. However, understanding the differences between HTTP PUT and POST is crucial for their correct usage.
Though, RFC 2616 has been very clear in differentiating between the two – yet complex wordings are a source of confusion for many of us. Let’s try to solve the puzzle of when to use PUT or POST methods.
1. Difference between PUT and POST
Let us start with the distinctions between these two HTTP methods to provide a comprehensive understanding.
| HTTP PUT | HTTP POST |
|---|---|
The HTTP specification clearly mentions that PUT method requests for the attached entity (in the request body) to be stored on the server that hosts the supplied Request-URI. If the Request-URI refers to an already existing resource – an update operation will happen, otherwise create operation should happen if Request-URI is a valid resource URI (assuming the client is allowed to determine the resource identifier). PUT /questions/{question-id} | The POST method requests that the origin server accept the entity attached in the request as a new subordinate of the resource identified by the Request-URI in the Request-Line. It essentially means that POST Request-URI should be of a collection URI. POST /questions |
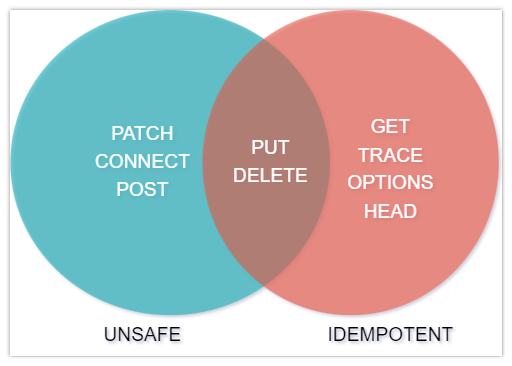
PUT method is idempotent. So if we retry a request multiple times, that should be equivalent to a single request invocation. | POST is NOT idempotent. So if we retry the request N times, we will end up having N resources with N different URIs created on the server. |
Use PUT when we want to modify a singular resource that is already a part of resource collection. PUT replaces the resource in its entirety. Use PATCH if the request updates part of the resource. | Use POST when you want to add a child resource under resources collection. |
Though PUT is idempotent, we should not cache its response. | Responses to this method are not cacheable, unless the response includes appropriate Cache-Control or Expires header fields. However, the 303 (See Other) response can be used to direct the user agent to retrieve a cacheable resource. |
Generally, in practice, use PUT for UPDATE operations. | Always use POST for CREATE operations. |
2. Choosing Between PUT and POST
To decide between HTTP PUT and POST, it’s essential to consider your specific use case:
- Use HTTP PUT when you want to update or create a specific resource at a known URI in an idempotent manner. This is suitable for scenarios where you have full control over resource replacement.
- Use HTTP POST when you need to submit data for processing, create new resources without specifying a URI, or perform non-idempotent operations.
3. PUT vs. POST with Example
Let’s say we are designing a network application. Let’s list down a few URIs and their purpose to get a better understanding of when to use POST and when to use PUT operations.
GET /device-management/devices : Get all devices
POST /device-management/devices : Create a new device
GET /device-management/devices/{id} : Get the device information identified by "id"
PUT /device-management/devices/{id} : Update the device information identified by "id"
DELETE /device-management/devices/{id} : Delete device by "id"Follow similar URI design practices for other resources as well.
4. Summary
Understanding the distinctions between HTTP PUT and POST and their respective use cases is pivotal to creating well-designed REST APIs. By following the suggestions discussed above, we can design robust APIs that are easy to deliver and maintain.
Happy Learning !!
Comments